“In this post, I’ll be showing you, an ordinary football fan like myself, how to make a basix xG model of your own in 20 minutes (or less).”
Even though famous football presenter, Jeff Sterling described expected goals (xG) as “the most useless stat in the history of football”, the metric has been accepted and used by several analysts and forward-thinking coaches. (If you are not familiar with xG please read this first).
In fact, the concept of xG has slowly worked its way into the mainstream, appearing even on television channels such as Sky Sports (Sterling’s employer).
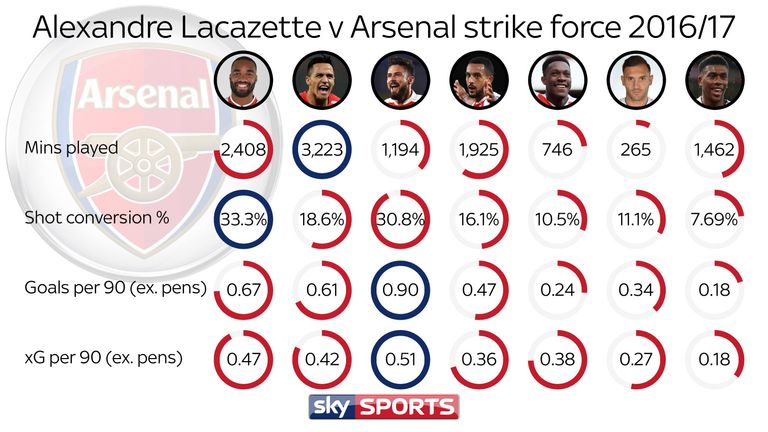
But while many have become familiar with the concept of xG, the models that actually generate xG values still seem like rocket science to most (I think data science is easier than rocket science. Otherwise I may soon have to rethink my career options.) In this post, I’ll be showing you, an ordinary football fan like myself, how to make a basic xG model of your own in 20 minutes (or less).
Finding a dataset
The first problem to solve when creating an xG model is finding a suitable dataset. Unfortunately, most useful football data is privately owned and you’d have to be extremely wealthy to afford it. As this blog hasn’t made me enough money (or any money for that matter), I spent several hours searching every corner of the internet for some free data. Luckily, I came across this awesome dataset on the data science website Kaggle. To download the data (it is an excel CSV file), you have to create an account first – but otherwise, it is completely free.
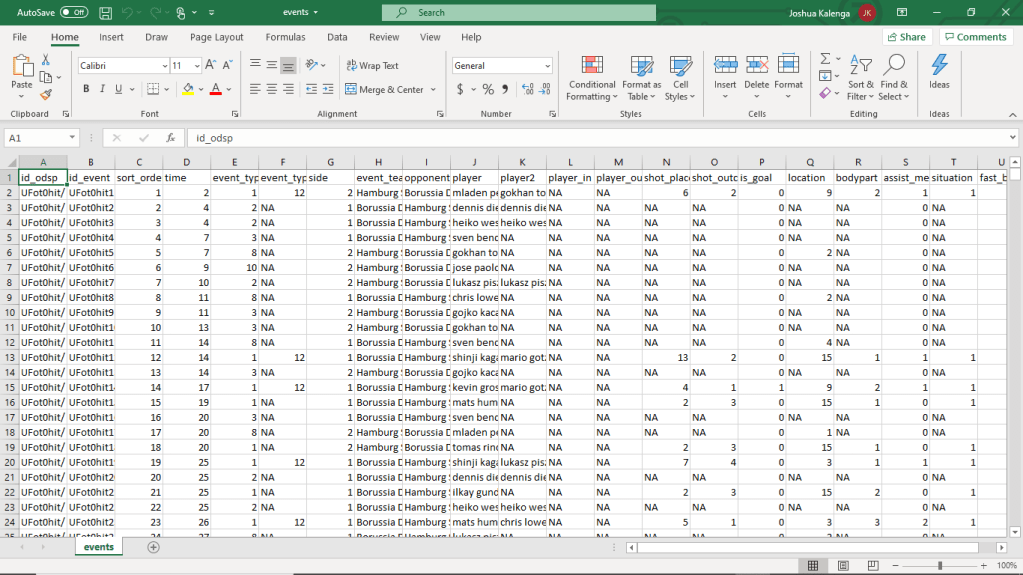
When you download the dataset from Kaggle (“events.csv”), be sure to also download the file “dictionary.txt” because it explains the variables (column names) contained in the data. Note that this is a dataset for a number of different events (shots, fouls, offsides, red cards etc) that occurred in “9,074 games … from the biggest 5 European football (soccer) leagues … from [the] 2011/2012 season to [the] 2016/2017.” Each row represents a particular event. In building an xG model, we are only interested in shots taken, which, if you read the “dictionary.txt” file, you will realise is any row in the data in which the value of the column “event_type” is 1.

With the dataset downloaded, take some time to perhaps browse through it and familiarize yourself with some of its variables as detailed in the “dictionary.txt” file. Otherwise, you may continue on your quest to build an xG model of your own.
Reading the dataset to calculate xG values
Before we continue, recall that xG is simply a probability that is calculated by observing how frequently a goal is scored from a given situation. It is important to define exactly what makes a particular ‘situation’. In this case, based on our dataset, we will define a situation using:
1. Location (where on the pitch the shot was taken)
2. Assist method (What led to the shot? Pass, cross etc)
3. Game situation (Was the shot from open-play? A set-piece?)
Other xG models may also include variables such as defensive pressure (how many defenders were around when the shot was being taken). But I think these 3 variables, though certainly not extensive, allow for a fairly sophisticated model.
Note, once again, that the variables contained in this particular dataset are number coded and the meaning of the codes can be found in the “dictionary.txt” file. For example, a penalty in this dataset would be coded as follows:
1. Location = 14 (in the “dictionary.txt” file, location #14 is “penalty spot”)
2. Assist method = 0 (in the “dictionary.txt” file, assist method #0 is “none”)
3. Game situation = 2 (in the “dictionary.txt” file, game situation #2 is “set-piece”)
Now, using this basic information, we can calculate the xG value for a penalty. Once again (and I know I keep repeating this), recall that xG is simply a probability that is calculated by observing how often a goal is scored from a given situation.
Therefore, to calculate the xG value for a penalty, we simply need to find each row in the dataset that corresponds to a penalty (using the code: location = 14, assist method = 0, game situation = 2) and then check if that penalty resulted in a goal. To check if a penalty (or any given shot) resulted in a goal, simply use the binary “is_goal” column. If the value in that column is a 1, a goal was scored. If it is 0, no goal was scored.
Keep two tallies – one that records “total penalties taken” and another that records “total goals”. Every time you find a penalty that was scored, increase both tallies by one. If you find a penalty that was missed, only increase the total penalties tally (by one). After you have done this for all penalties in the dataset, calculating the xG value is straightforward. You simply need to divide the “total goals” by the “total penalties taken”. For example, if you found that 77 goals were scored and 100 total penalties were taken, your xG value would be 77/100 – which is 0.77.

I hope that it is clear that the process above can be used to find xG values for many different situations. I only used a penalty as an example for simplicity sake. But if you’re anything like me, you must be thinking, “How tedious! Do I really need to do all that to find an xG value just for one single situation? And there must be hundreds more situations!”
Luckily for us, there are tools that we can use to do this process for us automatically. I happen to use Java, a programming language, as my tool but you could certainly do the same with other programming languages and even Microsoft Excel.
So, there you go! You just built (or learnt how to build) an xG model in (hopefully) 20 mins (ish). I hope that xG models now seem to you less like rocket science and more like basic division!
*This post (and it’s title) was inspired by this post, one of the first that I came across when I first took an interest in football analytics. I hope my work will inspire others the same way nerdy blogs such as the one above inspired me.
